Details
Please consider that the implementation of the method is still in an early stage and demonstrates conceptually the idea and application case.
Discovery of data useful for data analytics in big data relies increasingly on the integration and composition of data from disparate sources including derived data from prior analysis/processing. Yet, computer systems currently do not support sharing, re-finement, and repetition adequately enough to keep pace with rapid increases in data volume and diversity of data sources. Furthermore, access to these sources is complicated by the requirement that the users have to keep track “where” the data and services are instead of “what” they are.
We propose a novel architecture that treats the various data sources as “data services” and builds a platform for data integration, analysis, aggregation, and preservation of derived result data. The proposed infrastructure provides a stable, secure, and reliable data network with ?rst-class primitives for managing heterogeneous data services, for filtering, curating, aggregating, annotating, and naming collections of data from multiple data services. Derived results are captured and become first-class data products that can serve as new data services available for further processing/analysis. Data is decoupled from location, storage, security, and retrieval low-level primitives. Instead, it is accessed, exchanged, and shared by “name” or by “semantic attributes” that are meaningful to the users. This proposal shares some of the principles of that of Content-Centric Networking although the emphasis there is on the networking part rather than data.
Modelling Procedure
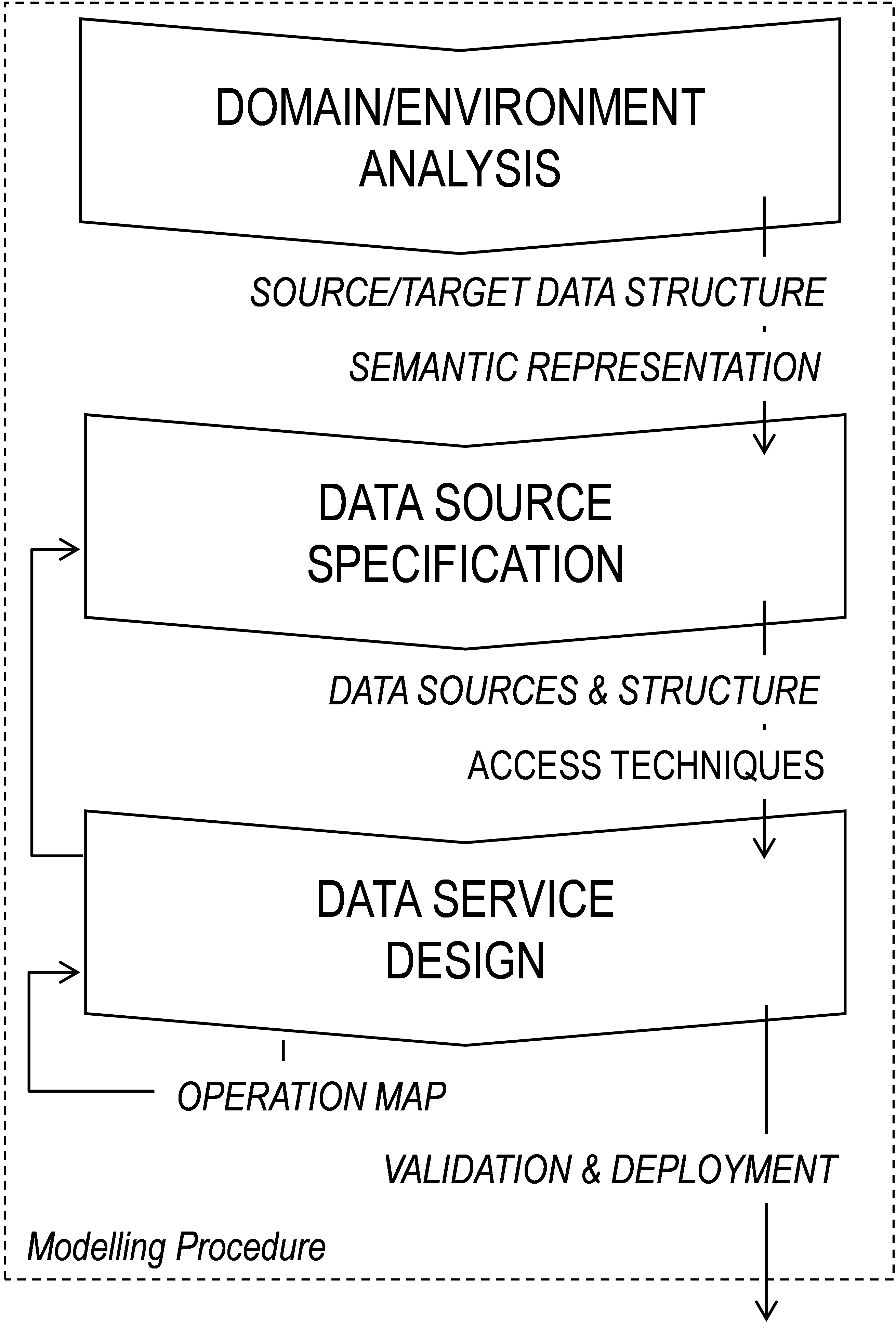
Step 1: Domain/Environment Analysis.
The initial step in for the method deals with understanding the functionality and mapping the required structure/schema, representation and semantics for input of the data service and its output. The modeler has to understand what the data consuming functionality needs, defines the interaction format and describes the semantics. Data service management aspects (concurrency, consistency, notification, update intervals) are identified and mapped using the result concept. This step is performed manually by the modeler; during deployment a web-service with the format, structure and message schema is exposed by the system.
Step 2: Data Source Specification.
Based on the result definition, sources are specified. This specification task builds on the business understanding [8] resulting from step 1. The modeler uses the access concept to define all necessary sources to cover the data requirements. This specification is not limited to structural or representational consideration but aims to cover all needed schema requirements. This step is performed interactively. The modeler maps the logical access mechanisms and interactively retrieves the schema from the underlying data source.
Step 3: Data Service Design.
The actual design phase aims to map source and required target schema. Various operations as initially defined in [3] build the basis for this design tasks. The design is performed hierarchically; each operation results in another extended, combined, composed data source that can be further refined. As a structuring element we distinguish between operation on Access (data, metadata retrieval), Query (filtering, aligning, composing, retrieving) and Result (return/serialization, persisting, updating and publication). This step is also performed iteratively. Each iteration is a refinement of previous models, further closing the gap between source and result specification.
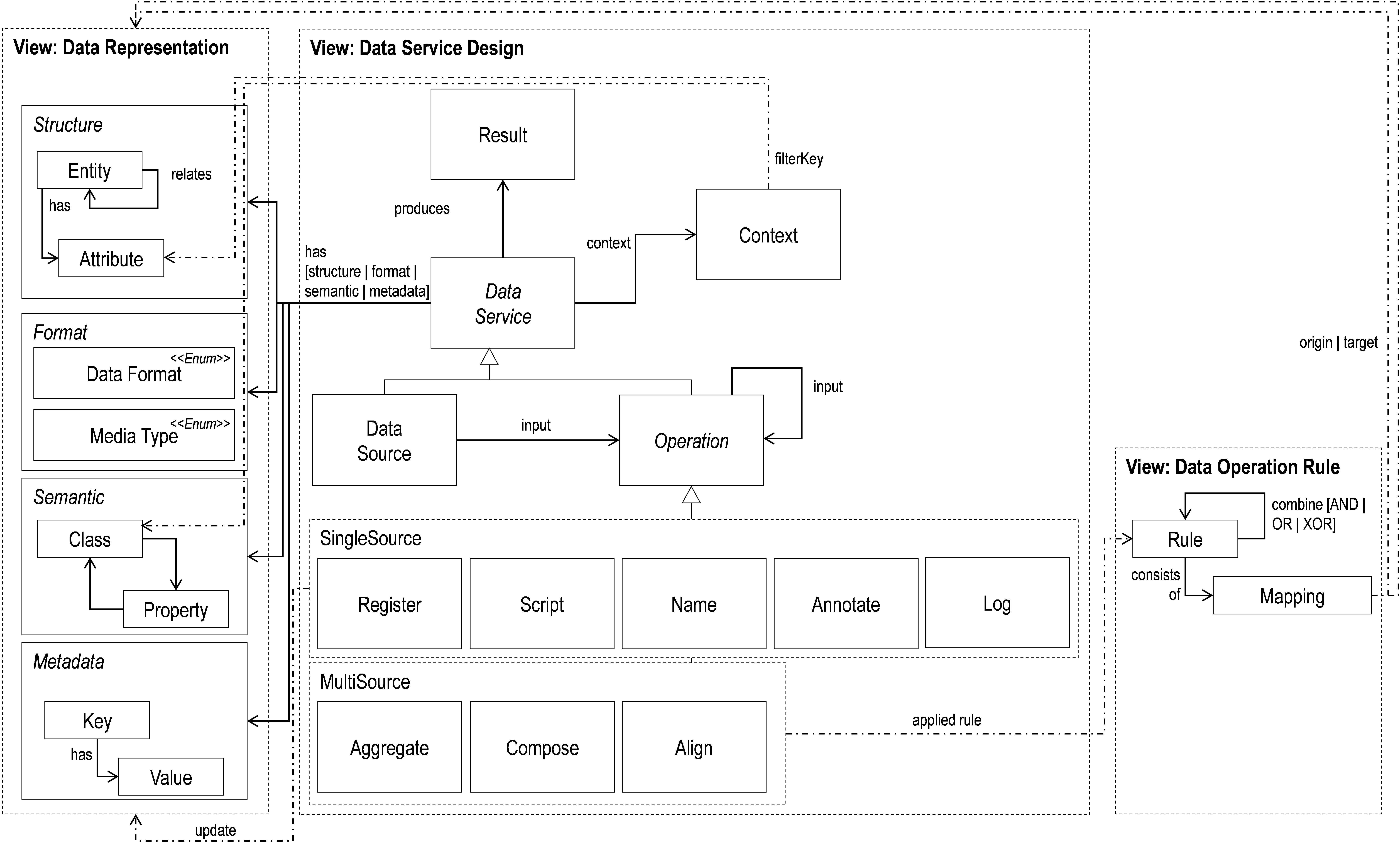
Modelling Language
The modelling language represents the structural perspective of the modelling method. The diagram below shows a platform independent representation of the class hierarchy and syntax; the relevant classes and their relations are mapped. A platform-dependent representation is provided in section 4 used for the proof-of-concept implementation.